
Proyectos y formación en los que estoy trabajando
Aquí reúno los cursos, plataformas y herramientas en los que estoy invirtiendo mi tiempo actualmente — proyectos donde la teoría se convierte en impacto real.
Datoscout

Construye tu primera Claude Skill
Automatiza tu trabajo con IA · cohorte 01
Curso de 6 sesiones (20h en vivo + 20h proyecto) donde cada participante sale con una Claude Skill propia funcionando sobre una tarea repetitiva real de su trabajo. No es teoría de IA: es construir una automatización que ahorra horas a la semana y queda corriendo. Cubre Cowork mode, skills built-in (xlsx, docx, pdf, pptx), Claude in Office, anatomía de SKILL.md, conexión a MCPs (Notion, Gmail, Drive) y subagentes. Corte de validación en S5 — quien entrega skill + MCP funcionando recibe certificado de validación.
Duración
20 h en vivo + 20 h proyecto
Precio
$148 USD
Sesiones
30 may – 14 jun 2026
Herramientas
Módulos
- 1Fundaciones + Project Brief
- 2Cowork mode + Skills built-in
- 3PowerPoint + Claude in Office
- 4Construye tu Skill v1
- 5Skill v2 + MCP (corte de validación)
- 6Subagentes + Demo final

Datoscout · Cohorte 01 · Ecuador 2026
SEE × Datoscout

IA Generativa Práctica
20 Horas para Automatizar tu Trabajo
Curso de vulgarización de herramientas de IA generativa. Sin código. Herramientas reales. Resultados el mismo día. Diseñado para que cualquier profesional en Ecuador pueda entender qué es la IA generativa y empezar a usarla eficazmente en su trabajo real.
Duración
40 h
Precio
$78.90 USD
Sesiones
Ene – Feb 2026
Herramientas
Módulos
- 1Fundamentos de IA Generativa
- 2IA / ML / Deep Learning
- 3Herramientas y casos prácticos
- 4Ética y uso responsable

Sociedad Ecuatoriana de Estadística × Datoscout
Datoscout

Crea Chatbots Inteligentes con IA
Capacidades, herramientas y oportunidades
Curso técnico práctico en Ecuador (Datoscout) sobre cómo construir asistentes conversacionales reales con LLMs: desde los fundamentos de APIs y RAG hasta bases vectoriales con FAISS, fine-tuning y el despliegue de un chatbot completo con Streamlit sobre AWS EC2. Continuación natural del curso de IA Generativa: mismo enfoque práctico, ahora con código.
Duración
12 h
Precio
$35 USD
Sesiones
Jun – Jul 2025
Herramientas
Módulos
- 1Fundamentos técnicos: LLMs, APIs y RAG
- 2Asistentes con recuperación contextual (RAG)
- 3Fine-tuning y personalización de modelos
- 4Bases vectoriales y búsqueda semántica con FAISS
- 5Chatbot completo: API, Streamlit y despliegue en EC2

Datoscout · Ecuador

Pipeline de inteligencia documental — arquitectura de extremo a extremo
Analitika
Plataforma Inteligente de Análisis Documental
Inteligencia documental para una institución gubernamental francesa
Plataforma integral de inteligencia documental construida para la División Numérique de un Ministerio Social francés. Ingesta documentos no estructurados, extrae y estructura contenido mediante inferencia LLM local, y realiza clasificación automatizada con validación humana en el bucle. Desplegada 100% on-premise para soberanía total de datos. Reconocida como "Cliente Referente en Innovación IA" por el cliente.
“Este proyecto superó nuestras expectativas. Ha transformado fundamentalmente nuestras capacidades de análisis documental.”
Periodo
Jul 2025 – Feb 2026
Equipo
3 ingenieros
Modelo
120B parámetros
Despliegue
100% on-premise
Validación
Validación humana en el bucle
Reconocimiento
Cliente Referente en Innovación IA
Stack técnico
Capacidades
- 1Pipeline modular: extracción de texto, transformación, inferencia LLM
- 2Inferencia LLM local vía vLLM (modelo instruct de 120B parámetros)
- 3Votación multi-completion para salidas JSON estructuradas robustas
- 4Pre-clasificación NLP basada en TF-IDF con validación Pydantic
- 5Framework de evaluación basado en ROUGE (precisión, recall, F1)
- 6Despliegue 100% on-premise — cero datos transmitidos al exterior

Pipeline de inteligencia de contenidos — arquitectura end-to-end
Analitika
Plataforma de Inteligencia y Monitoreo de Contenidos
Inteligencia de contenidos multi-país para un líder B2B europeo
Plataforma integral de inteligencia de contenidos construida para un importante distribuidor B2B europeo a través de una agencia digital francesa líder. Descubre, rastrea e indexa automáticamente contenido web en 19 países y 18 idiomas, lo compara contra una biblioteca de contenido maestra mediante matching semántico con IA, y presenta hallazgos a través de dashboards interactivos y reportes automatizados. Desplegada en AWS con contenedorización completa. Reconocida como “Cliente Referente en Innovación de IA y Datos.”

“Entregó una solución robusta y escalable con visibilidad total sobre el contenido en todos los mercados. El rigor técnico, la entrega confiable y la comunicación clara durante todo el proyecto fueron ejemplares.”
Período
Ago 2024 – Presente
Rol
Lead Data Scientist & Solutions Architect
Alcance
Multi-país, multi-idioma
Despliegue
AWS (Fargate, S3, SQS)
Interfaz
Streamlit + Cognito auth
Reconocimiento
Cliente Referente en Innovación de IA y Datos
Stack técnico
Capacidades
- 1Descubrimiento automatizado de sitemaps multi-país y multi-idioma con extracción de URLs
- 2Ingesta de biblioteca de contenido maestra con generación de embeddings IA
- 3Matching semántico cross-language vía similitud de embeddings
- 4Análisis de calidad SEO y etiquetado de contenido con IA (vacíos, duplicados, inconsistencias)
- 5Dashboards interactivos en Streamlit con autenticación AWS Cognito
- 6Reportes HTML automatizados por email y notificaciones Teams a stakeholders
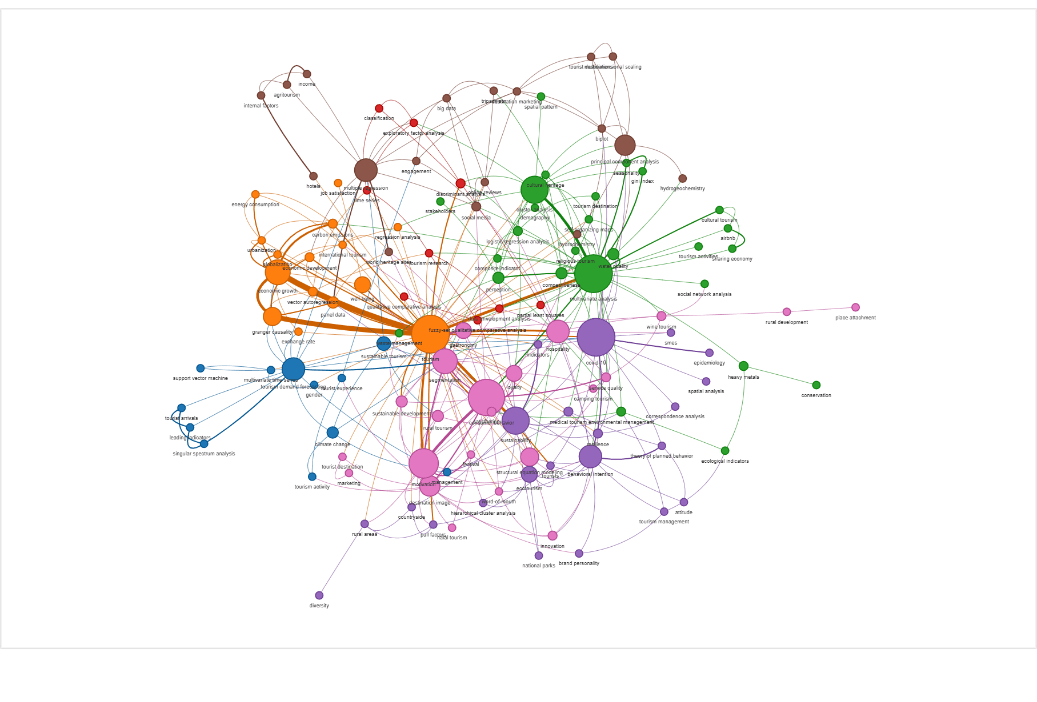
Red de co-ocurrencia de keywords — 124 nodos, 365 aristas, 8 comunidades
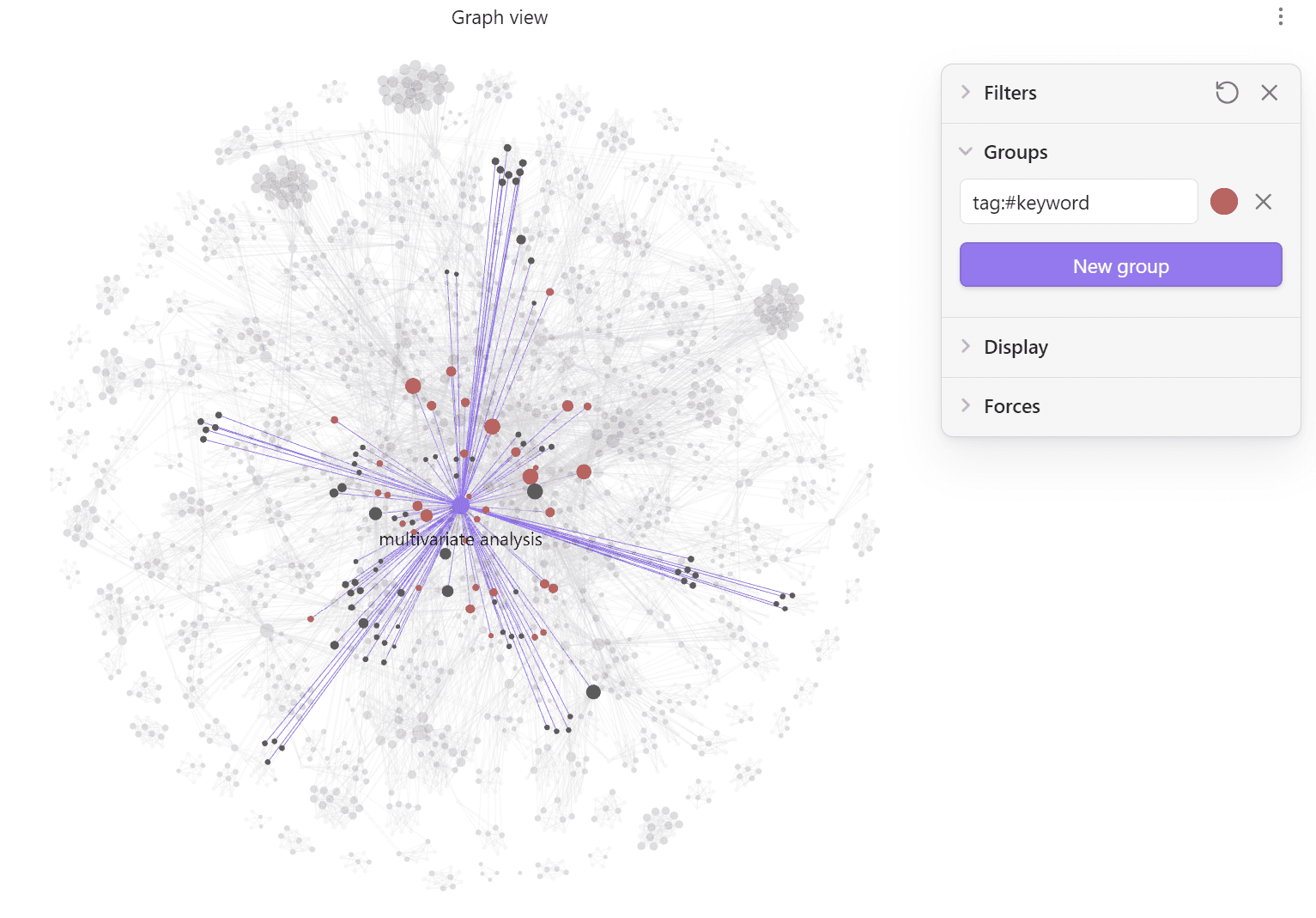
Vault de Obsidian — exploración interactiva con graph view
Analitika
Análisis Bibliométrico con Grafos de Co-ocurrencia
Técnicas multivariadas en investigación turística
Pipeline completo de análisis bibliométrico sobre 331 artículos científicos de Web of Science (2017–2024). Construye redes de co-ocurrencia de keywords, detecta comunidades temáticas, calcula centralidades y analiza la evolución temporal de las técnicas estadísticas multivariadas en turismo. Incluye generación automática de un vault de Obsidian para exploración interactiva.
Artículos
331
Keywords
124
Co-ocurrencias
365
Comunidades
8
Stack técnico
Capacidades
- 1Redes de co-ocurrencia, co-autoría y co-citación
- 2Detección de comunidades (Louvain / Leiden)
- 3Centralidades y huecos estructurales (Burt)
- 4Reducción dimensional (MDS, t-SNE, UMAP, CA biplot)
- 5Vault de Obsidian con graph view interactivo

