
Projects & Courses
Here I gather the courses, platforms, and tools where I'm investing my time right now — projects where theory turns into real impact.
Datoscout

Build your first Claude Skill
Automate your work with AI · cohort 01
6-session course (20h live + 20h project work) where every participant leaves with their own Claude Skill running on a real repetitive task from their work. Not AI theory: build an automation that saves hours weekly and keeps running on its own. Covers Cowork mode, built-in skills (xlsx, docx, pdf, pptx), Claude in Office, SKILL.md anatomy, MCP connections (Notion, Gmail, Drive) and subagents. Validation milestone at S5 — those who deliver a working skill + MCP receive validation certificate.
Duration
20 h en vivo + 20 h proyecto
Price
$148 USD
Sessions
30 may – 14 jun 2026
Tools
Modules
- 1Foundations + Project Brief
- 2Cowork mode + Built-in skills
- 3PowerPoint + Claude in Office
- 4Build your Skill v1
- 5Skill v2 + MCP (validation milestone)
- 6Subagents + Final demo

Datoscout · Cohort 01 · Ecuador 2026
SEE × Datoscout

IA Generativa Práctica
Applied Generative AI: 40 Hours to Automate Your Work
Introductory course on generative AI tools for professionals. No code. Real tools. Same-day results. I designed and delivered this course so that any professional can understand what generative AI is and start using it effectively in their daily work.
Duration
40 h
Price
$78.90 USD
Sessions
Ene – Feb 2026
Tools
Modules
- 1GenAI Fundamentals
- 2AI / ML / Deep Learning
- 3Tools & real-world cases
- 4Ethics & responsible use

Sociedad Ecuatoriana de Estadística × Datoscout
Datoscout

Build Intelligent Chatbots with AI
Capabilities, tools & opportunities
Hands-on technical course in Ecuador (Datoscout) on building real conversational assistants with LLMs: from API and RAG fundamentals to vector stores with FAISS, fine-tuning, and deploying an end-to-end chatbot with Streamlit on AWS EC2. The natural follow-up to the Generative AI course — same practical approach, now with code.
Duration
12 h
Price
$35 USD
Sessions
Jun – Jul 2025
Tools
Modules
- 1Technical fundamentals: LLMs, APIs & RAG
- 2Retrieval-augmented assistants (RAG)
- 3Fine-tuning & model customization
- 4Vector stores & semantic search with FAISS
- 5End-to-end chatbot: API, Streamlit & EC2 deployment

Datoscout · Ecuador

Document intelligence pipeline — end-to-end architecture
Analitika
Intelligent Document Analysis Platform
Document intelligence for a French government institution
End-to-end document intelligence platform built for the Digital Division of a French Social Ministry. Ingests unstructured documents, extracts and structures content through local LLM inference, and performs automated classification with human-in-the-loop validation. Deployed 100% on-premise for full data sovereignty. Awarded "Reference Client in AI Innovation" by the client.
“This project exceeded our expectations. It has fundamentally transformed our document analysis capabilities.”
Period
Jul 2025 – Feb 2026
Team
3 engineers
Model
120B parameters
Deployment
100% on-premise
Validation
Human-in-the-loop
Recognition
Reference Client in AI Innovation
Tech stack
Capabilities
- 1Modular pipeline: text extraction, transformation, LLM inference
- 2Local LLM inference via vLLM (120B-parameter instruct model)
- 3Multi-completion voting for robust structured JSON outputs
- 4TF-IDF-based NLP pre-classification with Pydantic validation
- 5ROUGE-based evaluation framework (precision, recall, F1)
- 6100% on-premise deployment — zero data transmitted externally

Content intelligence pipeline — end-to-end architecture
Analitika
Content Intelligence & Monitoring Platform
Multi-country content intelligence for a European B2B leader
End-to-end content intelligence platform built for a major European B2B distributor via a leading French digital agency. Automatically discovers, crawls, and indexes web content across 19 countries and 18 languages, compares it against a master content library using AI-powered semantic matching, and surfaces findings through interactive dashboards and automated reporting. Deployed on AWS with full containerization. Awarded “Reference Client in AI & Data Innovation.”

“Delivered a robust, scalable solution with full visibility over content across markets. Technical rigor, reliable delivery, and clear communication throughout the engagement were exemplary.”
Period
Aug 2024 – Present
Role
Lead Data Scientist & Solutions Architect
Scope
Multi-country, multi-language
Deployment
AWS (Fargate, S3, SQS)
Interface
Streamlit + Cognito auth
Recognition
Reference Client in AI & Data Innovation
Tech stack
Capabilities
- 1Automated multi-country, multi-language sitemap discovery and URL extraction
- 2Master content library ingestion with AI embedding generation
- 3Cross-language semantic matching via embedding similarity
- 4SEO quality analysis and AI-driven content labeling (gaps, duplicates, inconsistencies)
- 5Interactive Streamlit dashboards with AWS Cognito authentication
- 6Automated HTML email reports and Teams notifications to stakeholders
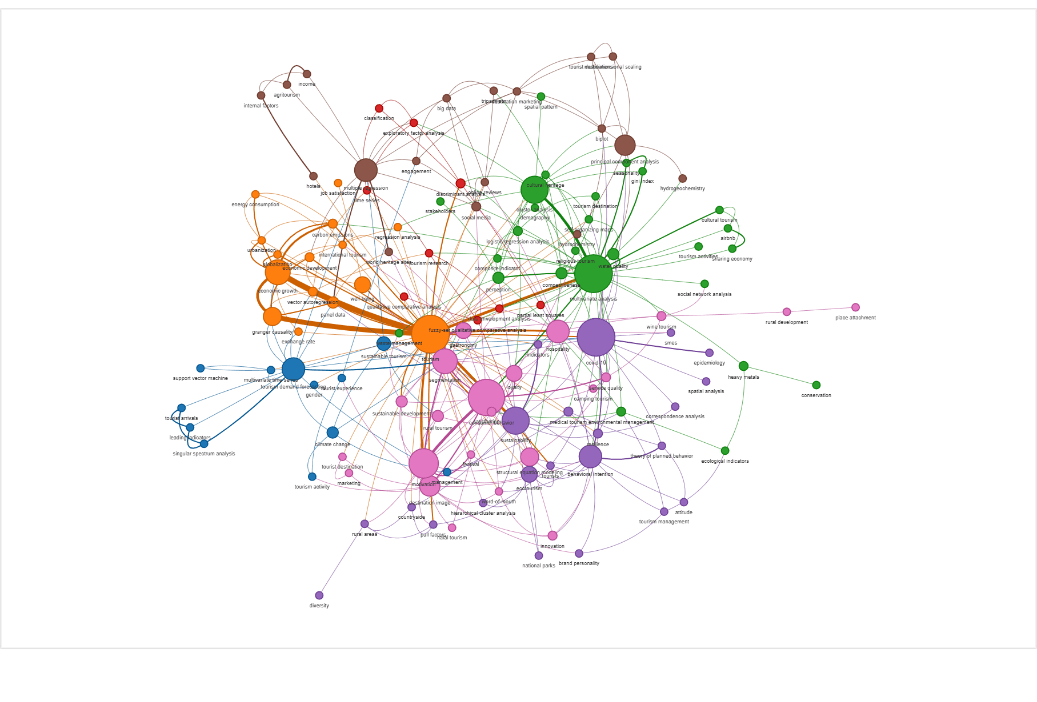
Keyword co-occurrence network — 124 nodes, 365 edges, 8 communities
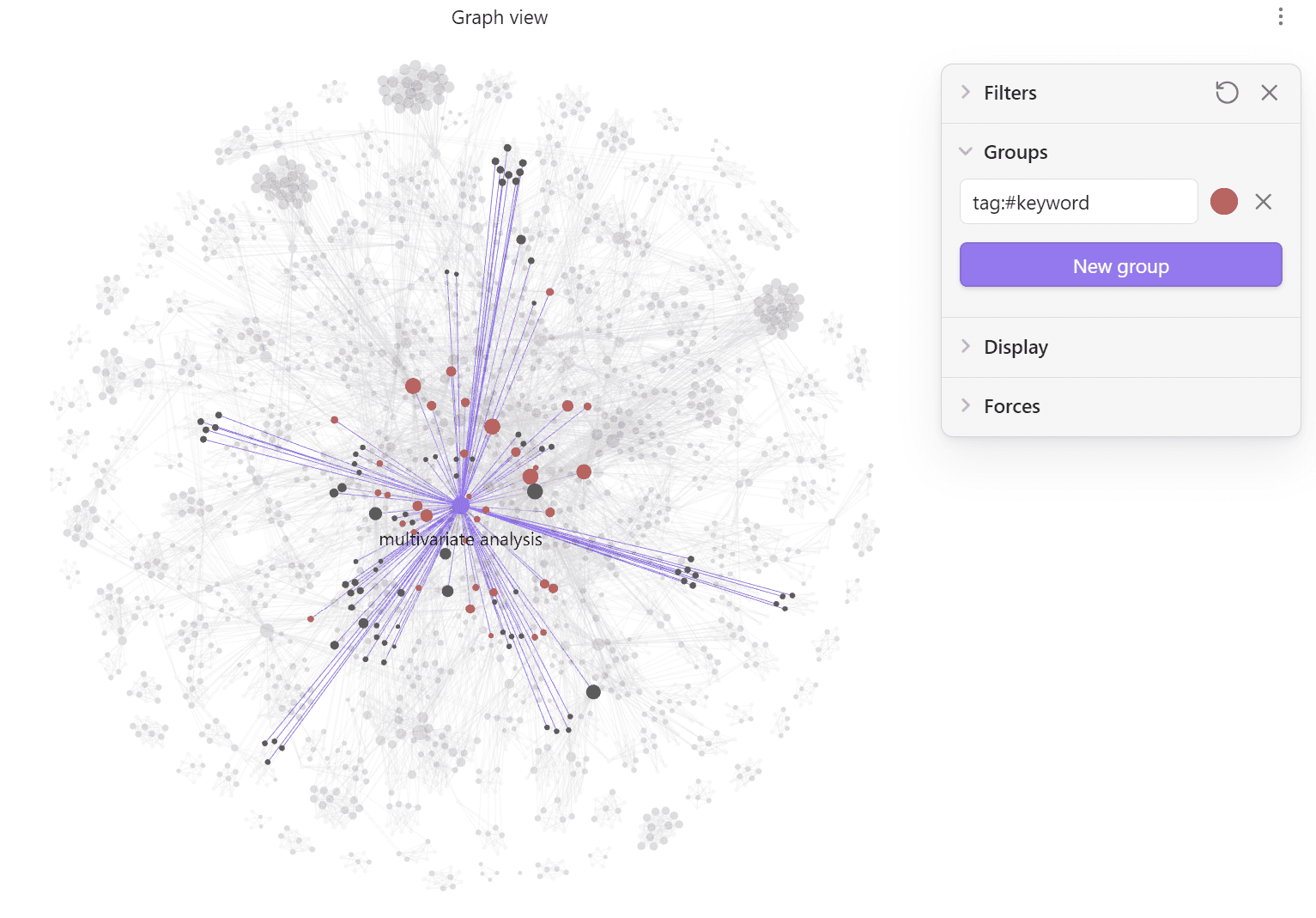
Obsidian vault — interactive exploration with graph view
Analitika
Bibliometric Analysis with Co-occurrence Graphs
Multivariate techniques in tourism research
End-to-end bibliometric analysis pipeline over 331 Web of Science articles (2017–2024). Builds keyword co-occurrence networks, detects thematic communities, computes centralities, and analyzes the temporal evolution of multivariate statistical techniques in tourism. Includes automatic generation of an Obsidian vault for interactive exploration.
Articles
331
Keywords
124
Co-occurrences
365
Communities
8
Tech stack
Capabilities
- 1Co-occurrence, co-authorship, and co-citation networks
- 2Community detection (Louvain / Leiden)
- 3Centralities and structural holes (Burt)
- 4Dimensionality reduction (MDS, t-SNE, UMAP, CA biplot)
- 5Obsidian vault with interactive graph view

